
A mesterséges intelligencia (MI) területének egyik legdinamikusabban fejlődő és legígéretesebb ága a mesterséges neurális hálózatok (MNH) világa. Ezek a komplex rendszerek az emberi agy működését hivatottak utánozni, lehetővé téve a gépek számára, hogy hatalmas mennyiségű adatból tanuljanak, mintázatokat ismerjenek fel, és összetett döntéseket hozzanak. A mélytanulás alapját képező neurális hálózatok forradalmasították a számítástechnikát, és ma már számos hétköznapi alkalmazásban találkozhatunk velük, a képfelismeréstől a természetes nyelvi feldolgozásig.
A neurális hálózatok ereje abban rejlik, hogy képesek adaptív módon feldolgozni az információkat. Nem programozzuk be őket explicit szabályokkal, hanem adatokon keresztül „tanulnak”, finomítva belső paramétereiket, hogy egyre pontosabb eredményeket produkáljanak. Ez a rugalmasság és öntanuló képesség teszi őket kiváló eszközzé olyan feladatok megoldására, amelyek hagyományos algoritmikus megközelítéssel rendkívül nehezen, vagy egyáltalán nem lennének kezelhetők. A technológia mélyebb megértése kulcsfontosságú ahhoz, hogy felismerjük a benne rejlő potenciált és felelősségteljesen alkalmazzuk a jövő kihívásainak megoldásában.
A mesterséges neurális hálózatok története és inspirációja
A mesterséges neurális hálózatok koncepciója nem újkeletű; gyökerei egészen a 20. század közepére nyúlnak vissza. Az első jelentős mérföldkő 1943-ban volt, amikor Warren McCulloch és Walter Pitts publikálták dolgozatukat az idegsejtek működésének matematikai modelljéről. Ez a modell egy egyszerű logikai kapuként működő neuront írt le, amely képes volt bemeneti jelek alapján kimenetet generálni. Bár primitívnek tűnhet, ez fektette le a modern neurális hálózatok alapjait.
Az 1950-es években Frank Rosenblatt fejlesztette ki a Perceptront, egy olyan egyrétegű neurális hálózatot, amely képes volt bináris osztályozási feladatokat elvégezni. A Perceptron sikere nagy reményeket ébresztett a mesterséges intelligencia kutatói körében, de hamarosan kiderült, hogy korlátai vannak. Marvin Minsky és Seymour Papert 1969-es könyvükben rámutattak, hogy az egyrétegű Perceptron nem képes megoldani az ún. XOR-problémát, ami az MI-kutatásban egyfajta „AI-tél” kezdetét jelentette, és a neurális hálózatok iránti érdeklődés egy időre alábbhagyott.
A fordulat az 1980-as években következett be, amikor a kutatók felfedezték a visszaterjesztés (backpropagation) algoritmusát. Ez az algoritmus lehetővé tette a többrétegű neurális hálózatok hatékony tanítását, megoldva a korábbi Perceptron korlátait. A visszaterjesztés lényege, hogy a hálózat kimenetének hibáját visszavezeti a rétegeken keresztül, és ennek alapján módosítja a neuronok közötti kapcsolatok súlyait. Ezzel a módszerrel a hálózat képes volt komplexebb mintázatokat is megtanulni és felismerni.
A 21. század elején a számítási kapacitás drámai növekedése, a hatalmas adatkészletek elérhetősége és az új aktivációs függvények, valamint hálózati architektúrák (pl. konvolúciós és rekurrens hálózatok) megjelenése újraélesztette a neurális hálózatok iránti érdeklődést. Ezt az időszakot a mélytanulás (deep learning) robbanásszerű fejlődése fémjelzi, amely a több rejtett réteggel rendelkező neurális hálózatok tanítására utal. Ma már a mélytanulás a mesterséges intelligencia élvonalában jár, és folyamatosan feszegeti a gépi tanulás határait.
A mesterséges neurális hálózatok inspirációja az emberi agy rendkívüli képességéből fakad: a tanulás, az adaptáció és a mintafelismerés képességéből, még bizonytalan vagy hiányos adatok esetén is.
A mesterséges neuron alapvető működése
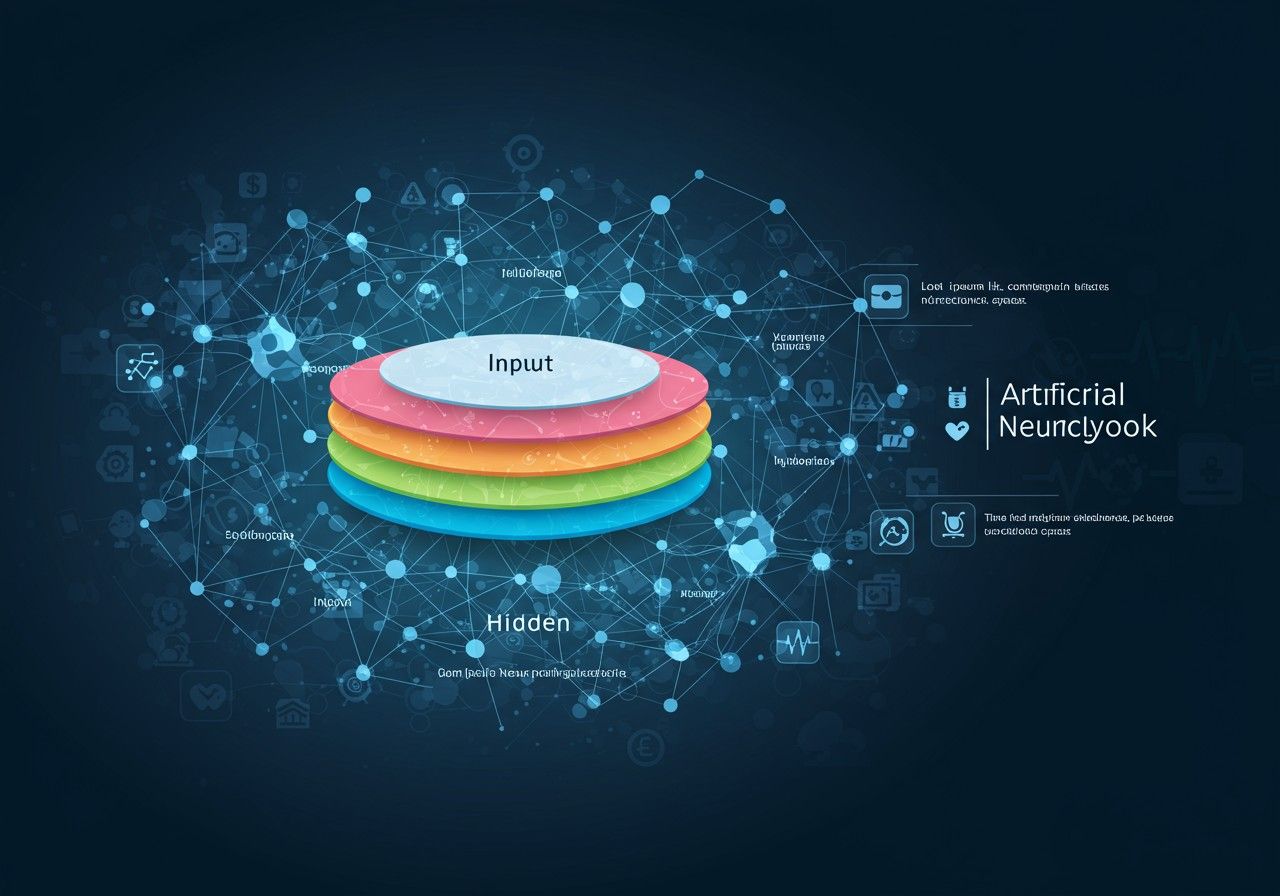
Egy mesterséges neurális hálózat alapköve a mesterséges neuron, vagy más néven perceptron. Ez a digitális egység az emberi agy biológiai neuronjainak egyszerűsített modellje. Bár a biológiai komplexitást nem reprodukálja teljes mértékben, a lényegi funkciókat modellezi: bemeneti jeleket fogad, feldolgozza azokat, majd kimeneti jelet generál.
Bemenetek és súlyok
Minden mesterséges neuron több bemeneti jelet kap (x1, x2, …, xn). Ezek a jelek lehetnek az adatkészlet jellemzői, vagy egy korábbi réteg neuronjainak kimenetei. Minden bemeneti jelhez tartozik egy súly (weight) (w1, w2, …, wn). A súlyok azt fejezik ki, hogy az adott bemenet mennyire fontos, vagy mennyire befolyásolja a neuron kimenetét. A súlyok kezdetben véletlenszerűen vannak inicializálva, és a tanulási folyamat során módosulnak.
Összegzés és torzítás (bias)
A neuron első lépése, hogy minden bemeneti jelet megszoroz a hozzá tartozó súllyal. Ezeket a súlyozott bemeneteket azután összeadja. Ez az összeg (Σwixi) adja meg a neuron „aktiválódás előtti” értékét. Ehhez az összeghez hozzáadódik még egy torzítás (bias) érték (b). A bias egyfajta eltolást biztosít, lehetővé téve a neuron számára, hogy akkor is aktiválódjon, ha minden bemenet nulla, vagy éppen ellenkezőleg, csak akkor, ha a bemenetek összessége egy bizonyos küszöböt meghalad. A bias érték is a tanulási folyamat során optimalizálódik.
Aktivációs függvény
Az összegzett és torzított érték (z = Σwixi + b) ezután egy aktivációs függvényen megy keresztül. Az aktivációs függvény feladata, hogy nemlineáris transzformációt végezzen az inputon, és meghatározza a neuron kimenetét. A nemlinearitás kulcsfontosságú, mert enélkül a neurális hálózat, bármennyi rétege is lenne, csak lineáris problémákat tudna megoldani. Különböző aktivációs függvények léteznek, amelyek eltérő tulajdonságokkal rendelkeznek:
- Szigma függvény (Sigmoid): Kimenete 0 és 1 közötti érték, gyakran használják bináris osztályozásnál. Problémája lehet a „vanishing gradient” jelenség.
- ReLU (Rectified Linear Unit): Gyakran használt függvény, kimenete 0, ha az input negatív, és megegyezik az inputtal, ha pozitív. Előnye a számítási hatékonyság és a vanishing gradient probléma enyhítése.
- Tanh (Hyperbolikus tangens): Hasonlít a szigma függvényhez, de kimenete -1 és 1 közötti.
- Softmax: Többosztályos osztályozási feladatoknál használatos az utolsó rétegben, valószínűségi eloszlást biztosít a lehetséges kimenetek között.
Az aktivációs függvény kimenete lesz a neuron végső kimeneti jele, amelyet továbbít a következő réteg neuronjainak, vagy ha ez a kimeneti réteg, akkor ez lesz a hálózat végső válasza.
A neurális hálózatok struktúrája és rétegei
A mesterséges neuronok önmagukban korlátozott képességekkel rendelkeznek. Az erejük a hálózatba rendezésükből fakad, ahol több rétegben kapcsolódnak egymáshoz, komplex struktúrákat alkotva. Egy tipikus mesterséges neurális hálózat három fő rétegtípust tartalmaz.
Bemeneti réteg (input layer)
Ez a réteg fogadja a nyers adatokat a külvilágból. Minden neuron a bemeneti rétegben egy-egy jellemzőt (feature) képvisel az adatkészletből. Például, ha képeket dolgozunk fel, a bemeneti réteg neuronjai a képpontok (pixelek) intenzitását reprezentálhatják. Ha szöveggel dolgozunk, a szavak vektoros reprezentációi lehetnek a bemenetek. A bemeneti réteg neuronjai nem végeznek számításokat, csupán továbbítják az adatokat a következő rétegnek.
Rejtett rétegek (hidden layers)
A bemeneti és kimeneti réteg között helyezkednek el a rejtett rétegek. Ezek a rétegek végzik a tényleges számításokat és a komplex mintázatok felismerését. Egy mély neurális hálózatnak több rejtett rétege van, innen ered a „mélytanulás” elnevezés. Minden rejtett réteg neuronjai az előző réteg összes neuronjához kapcsolódnak (teljesen összekapcsolt hálózatok esetén), és saját súlyokkal, biasokkal és aktivációs függvényekkel rendelkeznek. Ahogy az adatok áthaladnak a rejtett rétegeken, a hálózat egyre absztraktabb és komplexebb jellemzőket von ki belőlük. Például egy képfelismerő hálózat első rejtett rétegei éleket és textúrákat, míg a későbbi rétegek komplett objektumokat vagy azok részeit ismerhetik fel.
Kimeneti réteg (output layer)
A kimeneti réteg adja a hálózat végső válaszát. A neuronok száma ebben a rétegben a megoldandó feladattól függ.
- Regressziós feladatoknál (pl. házárak előrejelzése) általában egyetlen neuron van a kimeneti rétegben, amely egy folytonos értéket ad vissza.
- Bináris osztályozásnál (pl. igen/nem, macska/kutya) szintén egy neuron elegendő lehet, amelynek kimenetét egy szigma függvény 0 és 1 közé skálázza.
- Többosztályos osztályozásnál (pl. 10 különböző állatfaj felismerése) annyi neuron van a kimeneti rétegben, ahány osztályt megkülönböztetünk. Ilyenkor gyakran Softmax aktivációs függvényt használnak, amely valószínűségi eloszlást biztosít az osztályok között.
A kimeneti réteg tehát a feldolgozott információt emberi vagy gépi értelmezhető formába önti, befejezve az adatfeldolgozási folyamatot.
A tanulási folyamat: előre- és visszaterjesztés

A mesterséges neurális hálózatok valódi ereje a tanulási képességükben rejlik. Ez a folyamat két fő lépésből áll: az előreterjesztésből (forward propagation) és a visszaterjesztésből (backpropagation). Ezek ismétlődő ciklusokban zajlanak, amíg a hálózat teljesítménye el nem éri a kívánt szintet.
Előreterjesztés (forward propagation)
Az előreterjesztés az a folyamat, amikor a bemeneti adatok áthaladnak a hálózaton a bemeneti rétegtől a kimeneti rétegig. Lényegében ez a hálózat „tippelési” fázisa.
- A bemeneti réteg fogadja az adatokat.
- Az adatok minden neuronban súlyozva összeadódnak a bias értékkel, majd aktivációs függvényen mennek keresztül.
- A neuronok kimenetei a következő réteg bemeneteivé válnak.
- Ez a folyamat rétegről rétegre ismétlődik, amíg el nem éri a kimeneti réteget.
- A kimeneti réteg neuronjainak értékei adják a hálózat előrejelzését vagy válaszát az adott bemenetre.
Az előreterjesztés során a súlyok és biasok rögzítettek, és a hálózat egyszerűen kiszámítja az eredményt a jelenlegi paraméterek alapján. Ha a hálózat már betanult, akkor ez a fázis önmagában elegendő a predikciókhoz.
Veszteségfüggvény (loss function)
Miután a hálózat előrejelzést adott, szükség van egy mérőszámra, amely megmondja, mennyire pontos volt ez az előrejelzés. Erre szolgál a veszteségfüggvény (loss function), más néven költségfüggvény (cost function) vagy hibafüggvény. Ez a függvény számszerűsíti az eltérést a hálózat előrejelzése és a valós, kívánt kimenet között.
- Regressziós feladatoknál gyakran használják a négyzetes hibaátlagot (Mean Squared Error – MSE).
- Osztályozási feladatoknál a kereszt-entrópia (Cross-Entropy) a tipikus választás.
A tanulási folyamat célja a veszteségfüggvény értékének minimalizálása, vagyis a hálózat előrejelzéseinek minél közelebb juttatása a valós értékekhez.
Visszaterjesztés (backpropagation) és gradiens ereszkedés
A visszaterjesztés a neurális hálózatok tanulásának kulcsa. Ez az algoritmus felelős a súlyok és biasok módosításáért a veszteségfüggvény minimalizálása érdekében.
- Hiba kiszámítása: Először is kiszámítjuk a veszteségfüggvény értékét a hálózat kimenete és a valós címke alapján.
- Gradiens számítása: A visszaterjesztés algoritmusa ezután kiszámítja a veszteségfüggvény gradienseit (parciális deriváltjait) az összes súly és bias tekintetében. A gradiens egy vektor, amely a veszteségfüggvény legnagyobb növekedésének irányát mutatja.
- Súlyok frissítése: A gradiens ereszkedés (gradient descent) optimalizációs algoritmus segítségével a súlyokat és biasokat a gradiens ellentétes irányába módosítjuk. Ez azt jelenti, hogy „lefelé haladunk” a veszteségfüggvény felületén, a minimum felé. A módosítás mértékét a tanulási ráta (learning rate) paraméter szabályozza. Egy nagy tanulási ráta gyors, de potenciálisan instabil tanulást eredményezhet, míg egy kicsi lassú, de stabilabb konvergenciát biztosít.
Ez a két fázis – előreterjesztés és visszaterjesztés – iteratívan ismétlődik, amíg a hálózat el nem éri a megfelelő pontosságot, vagy amíg egy előre meghatározott számú epoch (tanulási ciklus) le nem telik. Egy epoch során a teljes tanító adatkészlet egyszer áthalad a hálózaton.
Optimalizációs technikák és hiperparaméterek
A neurális hálózatok hatékony tanításához nem elegendő pusztán a visszaterjesztés; számos optimalizációs technika és hiperparaméter finomhangolására is szükség van. Ezek a tényezők jelentősen befolyásolják a hálózat tanulási sebességét, stabilitását és végső teljesítményét.
Optimalizáló algoritmusok
A gradiens ereszkedés alapjaiban hatékony, de számos továbbfejlesztett változata létezik, amelyek gyorsabb és stabilabb konvergenciát biztosítanak.
- Stochastic Gradient Descent (SGD): Az alap gradiens ereszkedés, de minden egyes tanító példa után frissíti a súlyokat, ami gyorsabbá teszi, de zajosabb lehet.
- Mini-batch Gradient Descent: Kompromisszum az SGD és a teljes batch gradiens ereszkedés között. Egy kisebb adathalmazon (mini-batch) számolja a gradienst, ami hatékony és stabil.
- Momentum: Hozzáad egy „lendület” komponenst a súlyfrissítéshez, segítve a hálózatot a lokális minimumok elkerülésében és a gyorsabb konvergenciában.
- Adam (Adaptive Moment Estimation): Az egyik legnépszerűbb és leghatékonyabb optimalizáló. Adaptívan állítja be a tanulási rátát minden egyes súlyhoz külön-külön, figyelembe véve a gradiens első és második momentumát.
- RMSprop: Hasonló az Adamhez, szintén adaptív tanulási rátát használ, de csak a gradiens négyzetes momentumát veszi figyelembe.
Ezek az algoritmusok segítik a hálózatot abban, hogy hatékonyabban navigáljon a komplex veszteségfüggvény-felületen, elkerülve a lokális minimumokat és gyorsabban elérve a globális minimumot.
Hiperparaméterek
A hiperparaméterek olyan paraméterek, amelyeket a modell tanítása előtt kell beállítani, és nem a tanulási folyamat során optimalizálódnak (ellentétben a súlyokkal és biasokkal). A helyes hiperparaméter-választás kritikus a modell teljesítménye szempontjából.
- Tanulási ráta (learning rate): Meghatározza, mekkora lépésekben módosulnak a súlyok a gradiens ereszkedés során. Túl nagy érték esetén a hálózat túllőhet a minimumon, túl kicsi esetén pedig rendkívül lassan tanul.
- Batch méret (batch size): A mini-batch gradiens ereszkedésnél használt adathalmaz mérete. Kisebb batch méret zajosabb, de gyakori frissítéseket tesz lehetővé; nagyobb batch méret stabilabb, de ritkább frissítéseket eredményez.
- Epoch-ok száma (number of epochs): Hányszor haladjon át a teljes tanító adatkészlet a hálózaton. Túl kevés epoch alultanuláshoz (underfitting), túl sok epoch túltanuláshoz (overfitting) vezethet.
- Rejtett rétegek száma és neuronok száma rétegenként: Ezek határozzák meg a hálózat komplexitását. Túl kevés réteg vagy neuron nem képes komplex mintázatokat megtanulni, túl sok pedig túltanuláshoz vezethet és számításigényes.
- Aktivációs függvények típusa: A különböző rétegekben használt aktivációs függvények (pl. ReLU, Sigmoid, Tanh).
- Regularizációs paraméterek: L1/L2 regularizáció, dropout arány, amelyek segítenek a túltanulás megelőzésében.
A hiperparaméterek optimalizálása gyakran próbálgatással, rácskereséssel (grid search) vagy véletlenszerű kereséssel (random search) történik, de léteznek fejlettebb módszerek, mint például a Bayes-i optimalizálás is.
Túltanulás és alultanulás: a modell teljesítményének optimalizálása
A neurális hálózatok tanítása során az egyik legnagyobb kihívás a modell teljesítményének optimalizálása, elkerülve a túltanulás (overfitting) és az alultanulás (underfitting) jelenségét. Ezek a problémák rontják a modell általánosíthatóságát, azaz azt a képességét, hogy új, korábban nem látott adatokon is jól teljesítsen.
Alultanulás (underfitting)
Az alultanulás akkor fordul elő, amikor a modell túl egyszerű ahhoz, hogy megragadja az adatokban lévő alapvető mintázatokat. A modell rosszul teljesít mind a tanító adatkészleten, mind az új adatokon.
Jellemzői:
- Magas hibaarány a tanító adatkészleten.
- Hasonlóan magas hibaarány a validációs/teszt adatkészleten.
- A modell nem tanulta meg a lényeges összefüggéseket.
Okai:
- Túl kevés réteg vagy neuron a hálózatban (túl alacsony modellkomplexitás).
- Túl kevés epoch (a hálózat nem tanult eleget).
- Nem megfelelő jellemzők (feature-ök) a bemeneti adatokban.
- Túl erős regularizáció.
Megoldások:
- Növelni a hálózat komplexitását (több réteg, több neuron).
- Növelni az epoch-ok számát.
- Új, relevánsabb jellemzők hozzáadása.
- Csökkenteni a regularizáció mértékét.
Túltanulás (overfitting)
A túltanulás akkor következik be, amikor a modell túl jól alkalmazkodik a tanító adatokhoz, beleértve a zajt és a specifikus mintázatokat is, amelyek nem általánosíthatók új adatokra. Ennek eredményeként a modell kiválóan teljesít a tanító adatokon, de gyengén az új, nem látott adatokon.
Jellemzői:
- Nagyon alacsony hibaarány a tanító adatkészleten.
- Jelentősen magasabb hibaarány a validációs/teszt adatkészleten.
- A modell lényegében „memorizálta” a tanító adatokat, ahelyett, hogy megtanulta volna az alapvető mintázatokat.
Okai:
- Túl komplex modell (túl sok réteg, neuron).
- Túl sok epoch (a modell túl sokáig tanult).
- Túl kevés tanító adat a modell komplexitásához képest.
- Zajos vagy irreleváns jellemzők a bemeneti adatokban.
Megoldások:
- Több adat gyűjtése: Ez a legjobb megoldás, de nem mindig kivitelezhető.
- Adatnövelés (data augmentation): Képeknél forgatás, tükrözés, vágás; szövegeknél szinonimák cseréje, mondatszerkezet módosítása.
- Egyszerűbb modell: Csökkenteni a rétegek és neuronok számát.
- Early stopping: Leállítani a tanítást, amikor a validációs hiba elkezd növekedni.
- Regularizáció: Olyan technikák alkalmazása, amelyek büntetik a nagy súlyokat vagy inaktiválnak neuronokat, ezzel csökkentve a modell komplexitását.
- L1 és L2 regularizáció: Hozzáad egy büntető tagot a veszteségfüggvényhez, amely a súlyok abszolút értékét (L1) vagy négyzetét (L2) figyelembe veszi. Ez arra ösztönzi a modellt, hogy kisebb súlyokat használjon, csökkentve a túlzott illeszkedést.
- Dropout: A tanítás során véletlenszerűen inaktiválja a neuronok egy részét (pl. 20-50%-át). Ez arra kényszeríti a hálózatot, hogy robusztusabb jellemzőket tanuljon, és megakadályozza, hogy egy-egy neuron túlzottan támaszkodjon más neuronokra.
- Jellemzőválasztás (feature selection): Csökkenteni a bemeneti jellemzők számát, eltávolítva az irreleváns vagy redundáns adatokat.
A túltanulás és alultanulás közötti egyensúly megtalálása a mélytanulás egyik legfontosabb aspektusa, és gyakran iteratív folyamat, amely sok kísérletezést igényel.
A mesterséges neurális hálózatok típusai
A mesterséges neurális hálózatok nem egységes entitások; számos különböző architektúra létezik, mindegyik optimalizálva bizonyos típusú feladatokra és adatstruktúrákra. A legfontosabb típusok megértése kulcsfontosságú a megfelelő modell kiválasztásához.
Előrecsatolt neurális hálózatok (feedforward neural networks – FNN)
Ezek a legalapvetőbb neurális hálózatok, ahol az információ csak egy irányba, előre halad a bemeneti rétegtől a kimeneti rétegig, rétegről rétegre. Nincsenek ciklusok vagy visszacsatolások.
Jellemzők:
- Egyszerű felépítés.
- Minden neuron az előző réteg összes neuronjához kapcsolódik (teljesen összekapcsolt rétegek).
- Alkalmasak strukturált adatok (táblázatos adatok) feldolgozására, egyszerű osztályozási és regressziós feladatokra.
Alkalmazások:
- Egyszerű adatbesorolás.
- Prediktív modellezés táblázatos adatokon.
Konvolúciós neurális hálózatok (convolutional neural networks – CNN)
A CNN-ek forradalmasították a képfelismerés és a számítógépes látás területét. Különösen hatékonyak olyan adatok feldolgozásában, amelyek térbeli struktúrával rendelkeznek, mint például a képek.
Jellemzők:
- Konvolúciós rétegek: Szűrőket (kernelleket) alkalmaznak a bemeneti adatokra, hogy helyi mintázatokat (éleket, textúrákat, formákat) észleljenek. Ezek a szűrők a hálózat tanulása során optimalizálódnak.
- Pooling rétegek: Csökkentik a dimenzionalitást és a számítási terhelést, miközben megőrzik a fontos információkat (pl. max pooling).
- Teljesen összekapcsolt rétegek: A konvolúciós és pooling rétegek után általában egy vagy több teljesen összekapcsolt réteg következik, amely elvégzi a végső osztályozást vagy regressziót.
- Súlymegosztás (weight sharing): Ugyanazokat a szűrőket alkalmazzák a kép különböző részeire, ami csökkenti a paraméterek számát és segít a térbeli invariancia biztosításában.
Alkalmazások:
- Arcfelismerés.
- Objektumdetektálás.
- Orvosi képalkotás (pl. daganatok felismerése).
- Önvezető autók (környezet érzékelése).
Rekurrens neurális hálózatok (recurrent neural networks – RNN)
Az RNN-ek olyan hálózatok, amelyek képesek szekvenciális adatok feldolgozására, mint például szöveg, beszéd vagy idősorok. Különlegességük, hogy van „memóriájuk”, azaz figyelembe veszik az előző lépések kimeneteit a jelenlegi kimenet generálásakor.
Jellemzők:
- Visszacsatolt kapcsolatok, amelyek lehetővé teszik az információ áramlását a hálózaton belül időben.
- Problémájuk lehet a „vanishing gradient” és a „exploding gradient” hosszú szekvenciák esetén.
Variációk:
- LSTM (Long Short-Term Memory): Kifejezetten a hosszú távú függőségek kezelésére tervezték, „kapuk” (input, felejtés, output kapu) segítségével szabályozza az információ áramlását a memória cellájában.
- GRU (Gated Recurrent Unit): Hasonló az LSTM-hez, de egyszerűbb architektúrával, kevesebb paraméterrel, mégis hasonlóan hatékony.
Alkalmazások:
- Természetes nyelvi feldolgozás (NLP): gépi fordítás, szöveggenerálás, hangfelismerés.
- Idősor-előrejelzés (pl. tőzsdei árfolyamok).
- Videóelemzés.
Generatív adversariális hálózatok (generative adversarial networks – GAN)
A GAN-ok két neurális hálózatból állnak, amelyek egymás ellen versenyezve tanulnak: egy generátor és egy diszkriminátor.
Jellemzők:
- Generátor: Megpróbál valósághű adatokat (pl. képeket) generálni véletlen zajból.
- Diszkriminátor: Megpróbálja megkülönböztetni a valós adatokat a generátor által létrehozott hamis adatoktól.
- A két hálózat addig tanul, amíg a generátor olyan adatokat nem tud létrehozni, amelyeket a diszkriminátor már nem tud megkülönböztetni a valósaktól.
Alkalmazások:
- Valósághű képek generálása (pl. nem létező emberek arcképei).
- Kép-kép fordítás (pl. éjszakai képből nappali kép).
- Adatnövelés.
- Videógenerálás.
Transzformerek (transformers)
A transzformerek architektúrája az utóbbi években forradalmasította az NLP területét. A kulcsfontosságú eleme az önfigyelmi mechanizmus (self-attention mechanism), amely lehetővé teszi a modell számára, hogy a bemeneti szekvencia különböző részeire fókuszáljon, és megragadja a távoli függőségeket.
Jellemzők:
- Nincs rekurrencia, ami párhuzamosabb feldolgozást tesz lehetővé és gyorsabb tanítást.
- Kiválóan kezelik a hosszú távú függőségeket.
- Encoder-decoder struktúra, bár léteznek csak encoder (BERT) és csak decoder (GPT) alapú modellek is.
Alkalmazások:
- Gépi fordítás.
- Szövegösszefoglalás.
- Kérdés-válasz rendszerek.
- Szöveggenerálás (pl. GPT-3).
Ez a sokféleség mutatja a neurális hálózatok adaptálhatóságát és azt, hogy a kutatók folyamatosan új és hatékonyabb architektúrákat fejlesztenek ki a legkülönfélébb problémák megoldására.
Alkalmazási területek: hol találkozhatunk mesterséges neurális hálózatokkal?
A mesterséges neurális hálózatok és a mélytanulás ma már szinte minden iparágban jelen vannak, jelentősen átalakítva a technológiai képességeket és a mindennapi életünket. Az alábbiakban bemutatjuk a legfontosabb alkalmazási területeket.
Képfelismerés és számítógépes látás
Ez az egyik leglátványosabb terület, ahol a CNN-ek kiemelkedő teljesítményt nyújtanak.
- Arcfelismerés: A biztonsági rendszerektől az okostelefonok feloldásáig széles körben alkalmazzák.
- Objektumdetektálás: Önvezető autókban, ahol felismerik a gyalogosokat, járműveket, közlekedési táblákat. Ipari minőségellenőrzésben is használják.
- Orvosi képalkotás: Röntgensugarak, MRI és CT felvételek elemzése daganatok, betegségek vagy rendellenességek felismerésére, gyakran pontosabban, mint az emberi szem.
- Képbesorolás és címkézés: Automatikusan kategorizálják a képeket (pl. „kutya”, „táj”), vagy címkéket rendelnek hozzájuk.
- AR (kiterjesztett valóság) és VR (virtuális valóság): A valós idejű tárgyfelismerés és a térbeli megértés alapja.
Természetes nyelvi feldolgozás (NLP)
Az RNN-ek, LSTM-ek, GRU-k és különösen a transzformerek forradalmasították a gépek emberi nyelv megértésének és generálásának képességét.
- Gépi fordítás: A Google Translate és más fordítóprogramok alapja, amelyek egyre pontosabban és árnyaltabban fordítanak nyelvek között.
- Hangfelismerés és beszédszintézis: Virtuális asszisztensek (Siri, Alexa, Google Assistant), diktáló szoftverek és felolvasó rendszerek.
- Szövegbesorolás és hangulatelemzés: Spam szűrés, ügyfélszolgálati üzenetek kategorizálása, közösségi média bejegyzések hangulatának (pozitív, negatív, semleges) elemzése.
- Chatbotok és virtuális asszisztensek: Automatikus ügyfélszolgálati rendszerek, amelyek képesek párbeszédet folytatni és kérdésekre válaszolni.
- Szöveggenerálás és összefoglalás: Cikkek, jelentések automatikus írása, hosszú szövegek rövid összefoglalása.
Adat- és prediktív analitika
A neurális hálózatok kiválóan alkalmasak komplex adatmintázatok felismerésére és jövőbeli események előrejelzésére.
- Pénzügyi előrejelzés: Tőzsdei árfolyamok, devizaárfolyamok, hitelkockázat előrejelzése.
- Csalásfelismerés: Banki tranzakciók, biztosítási igények vagy online vásárlások elemzése potenciális csalások azonosítására.
- Ajánlórendszerek: Netflix, Amazon, Spotify – ezek a rendszerek a korábbi viselkedésünk alapján ajánlanak filmeket, termékeket vagy zenéket.
- Marketing és ügyfélviselkedés elemzése: Ügyfél szegmentálás, vásárlási szokások előrejelzése, célzott reklámozás.
- Kockázatelemzés: Biztosítási szektorban, hitelbírálatnál.
Robotika és automatizálás
A neurális hálózatok lehetővé teszik a robotok számára, hogy intelligensebben érzékeljék környezetüket és reagáljanak arra.
- Ipari robotok: Minőségellenőrzés, hibafelismerés, precíziós összeszerelés.
- Autonóm járművek: Nemcsak az önvezető autók, hanem drónok és más autonóm rendszerek is használják a környezet érzékelésére és a navigációra.
- Robotikus manipuláció: Objektumok felismerése, megfogása és manipulálása.
Orvostudomány és egészségügy
Az egészségügyi adatok (képek, szenzoradatok, genetikai információk) komplexitása ideális terepet biztosít a neurális hálózatok számára.
- Betegségek diagnosztizálása: Képalkotó diagnosztika (radiológia), patológia, bőrgyógyászat területén.
- Gyógyszerkutatás és -fejlesztés: Molekulák szűrése, gyógyszerkölcsönhatások előrejelzése, új vegyületek tervezése.
- Személyre szabott orvoslás: Genetikai adatok elemzése a legmegfelelőbb kezelési terápia kiválasztásához.
- Járványügyi előrejelzés: Betegségek terjedésének modellezése és előrejelzése.
- Szenzoradatok elemzése: Viselhető eszközökből származó adatok (pulzus, alvásminták) elemzése egészségügyi kockázatok azonosítására.
Művészet és kreatív iparágak
A generatív neurális hálózatok (különösen a GAN-ok) új lehetőségeket nyitottak a kreatív alkotásban.
- Zene- és képzőművészet generálása: Algoritmusok, amelyek új zeneműveket, festményeket vagy akár filmforgatókönyveket hoznak létre.
- Videójátékok: Intelligensebb NPC-k (nem játékos karakterek), procedurális tartalomgenerálás, játékos viselkedésének adaptív elemzése.
- Média manipuláció: Deepfake videók és képek generálása (etikai aggályokkal).
Ez a széles spektrum jól mutatja, hogy a mesterséges neurális hálózatok nem csupán elméleti konstrukciók, hanem gyakorlati, valós problémákat megoldó eszközök, amelyek folyamatosan formálják a jövőnket.
Kihívások és etikai megfontolások
A mesterséges neurális hálózatok rendkívüli képességeik mellett számos kihívást és komoly etikai kérdést is felvetnek. Ezekkel a problémákkal foglalkozni kell ahhoz, hogy a technológia előnyeit felelősségteljesen és fenntarthatóan aknázhassuk ki.
Adatok minősége és mennyisége
A neurális hálózatok teljesítménye nagymértékben függ az őket betanító adatok minőségétől és mennyiségétől.
- Adatgyűjtés: Hatalmas, releváns és annotált adatkészletek gyűjtése rendkívül költséges és időigényes lehet.
- Adatminőség: A zajos, hiányos vagy hibás adatok hibás, torzított modellhez vezethetnek. „Garbage in, garbage out” elv érvényesül.
- Adattorzulás (bias): Ha a tanító adatok nem reprezentatívak, vagy bizonyos csoportok felé torzítottak, a modell is torzított előrejelzéseket fog adni. Például, ha egy arcfelismerő rendszert túlnyomórészt világos bőrű emberek képeivel tanítanak, az gyengébben teljesíthet sötétebb bőrűeken.
Számítási erőforrások
A mély neurális hálózatok tanítása rendkívül számításigényes.
- Hardverigény: Erős GPU-k (grafikus feldolgozó egységek) vagy speciális AI chipek (TPU-k) szükségesek, amelyek drágák és energiaigényesek.
- Időigény: Egy komplex modell tanítása napokig, hetekig vagy akár hónapokig is eltarthat, még a legmodernebb hardvereken is.
- Környezeti hatás: Az MI-modellek tanításához szükséges energiafogyasztás jelentős szénlábnyomot hagyhat.
Magyarázhatóság (explainability) – a „fekete doboz” probléma
A neurális hálózatok, különösen a mélyhálózatok, gyakran „fekete dobozként” működnek. Nehéz megérteni, hogy pontosan milyen logika alapján jutnak el egy adott kimenethez.
- Bizalom hiánya: Ha nem tudjuk, miért hoz egy MI-rendszer egy adott döntést (pl. orvosi diagnózis, hitelbírálat), nehéz megbízni benne.
- Hibakeresés: Nehéz azonosítani és kijavítani a hibákat, ha nem értjük a modell belső működését.
- Jogi és etikai következmények: Ki a felelős, ha egy autonóm rendszer hibás döntést hoz, amely kárt okoz? A fejlesztő, az üzemeltető, vagy maga az MI?
Az Explanable AI (XAI) kutatási terület célja, hogy olyan módszereket fejlesszen ki, amelyekkel a neurális hálózatok döntései értelmezhetőbbé és magyarázhatóbbá válnak.
Adatvédelem és biztonság
A neurális hálózatok nagy mennyiségű személyes és érzékeny adatot dolgozhatnak fel, ami adatvédelmi és biztonsági kockázatokat rejt magában.
- Adatszivárgás: A tanító adatkészletek érzékeny információkat tartalmazhatnak, amelyek illetéktelen kezekbe kerülve visszaélésekre adhatnak okot.
- Adatbiztonság: A modellek sebezhetőek lehetnek rosszindulatú támadásokkal szemben, amelyek torzíthatják az előrejelzéseket vagy adatokat szivárogtathatnak ki.
- Deepfake technológia: A generatív hálózatok képesek rendkívül valósághű, de hamis képeket, videókat vagy hangfelvételeket létrehozni, ami dezinformációhoz és manipulációhoz vezethet.
Munkaerőpiaci hatások
Az automatizáció és az MI terjedése aggodalmakat vet fel a munkahelyek jövőjével kapcsolatban.
- Munkahelyek elvesztése: Bizonyos rutinfeladatokat vagy akár komplexebb munkaköröket is átvehetnek a gépek.
- Új munkahelyek teremtése: Ugyanakkor új típusú munkahelyek is keletkeznek az MI fejlesztésében, karbantartásában és felügyeletében.
- Átképzés szükségessége: A munkaerőnek alkalmazkodnia kell az új technológiai környezethez, ami folyamatos átképzést igényel.
Etikai irányelvek és szabályozás
A fenti kihívások miatt egyre sürgetőbbé válik az etikai irányelvek és a jogi szabályozás kidolgozása az MI fejlesztésére és alkalmazására vonatkozóan.
- Átláthatóság és elszámoltathatóság: A rendszereknek átláthatóan kell működniük, és egyértelműen azonosíthatónak kell lennie a felelősségnek.
- Méltányosság és diszkriminációellenesség: A modelleknek tisztességesen kell működniük mindenki számára, és nem szabad hátrányos megkülönböztetést alkalmazniuk.
- Adatvédelem és biztonság: Szabályozni kell az adatok gyűjtését, tárolását és felhasználását.
- Emberi felügyelet: Biztosítani kell az emberi beavatkozás és felügyelet lehetőségét, különösen kritikus döntéshozó rendszerek esetén.
Ezek a megfontolások alapvetőek ahhoz, hogy a mesterséges neurális hálózatok fejlődése ne csak technológiailag, hanem társadalmilag is előnyös legyen.
A mesterséges neurális hálózatok jövője és kilátásai
A mesterséges neurális hálózatok fejlődése ma is dinamikus, és a jövőben várhatóan még nagyobb áttöréseket hoz majd. A kutatók folyamatosan dolgoznak az új architektúrákon, a tanítási módszereken és az alkalmazási területek bővítésén.
Új architektúrák és modellek
A transzformerek sikere után a kutatók tovább vizsgálják az attention mechanizmusokat és a hálózatok skálázhatóságát. Várhatóan új, még hatékonyabb és specifikusabb feladatokra optimalizált architektúrák jelennek meg. A multimodális MI (olyan rendszerek, amelyek képesek több adattípus, pl. szöveg, kép, hang együttes feldolgozására) is egyre inkább előtérbe kerül, lehetővé téve a komplexebb valóságértelmezést.
Öntanuló rendszerek és megerősítéses tanulás
A megerősítéses tanulás (reinforcement learning), ahol a neurális hálózatok interakcióba lépnek egy környezettel és jutalmak, büntetések alapján tanulnak, hatalmas potenciált rejt magában. Ez a megközelítés lehetővé teszi a rendszerek számára, hogy önállóan fedezzenek fel optimális stratégiákat, például játékokban (AlphaGo) vagy robotikai feladatokban. A jövőben várhatóan egyre több autonóm rendszer fog ezen az elven működni, adaptívabb és rugalmasabb viselkedést mutatva.
Kvantum mesterséges intelligencia (Quantum AI)
A kvantum számítástechnika és a mesterséges intelligencia metszéspontjában létrejövő kvantum MI ígéretes, bár még gyerekcipőben járó terület. A kvantum-neurális hálózatok képesek lehetnek olyan komplex problémák megoldására, amelyek meghaladják a klasszikus számítógépek képességeit, különösen nagy adathalmazok feldolgozásában és mintafelismerésben. Bár még sok kutatásra van szükség, a kvantum MI gyökeresen megváltoztathatja a mesterséges intelligencia jövőjét.
Az általános mesterséges intelligencia (AGI) felé
A jelenlegi neurális hálózatok szűk MI-nek (narrow AI) minősülnek, azaz csak specifikus feladatok elvégzésére képesek. Az általános mesterséges intelligencia (AGI) célja olyan rendszerek létrehozása, amelyek képesek bármilyen intellektuális feladatot elvégezni, amit egy ember is tud. Bár ez a cél még távoli, a neurális hálózatok fejlődése, különösen a transzformerek és a multimodalitás irányába, lépésről lépésre közelebb visz ehhez a vízióhoz. A jövőben várhatóan az MI-rendszerek egyre inkább képesek lesznek absztrakt gondolkodásra, problémamegoldásra, és akár kreatív feladatok elvégzésére is.
A mesterséges neurális hálózatok nem csupán a technológiai fejlődés motorjai, hanem a tudományos felfedezések és a társadalmi innováció kulcsai is, amelyek a jövőben még mélyebben áthatják majd életünket.
Etikus és felelős fejlesztés
A technológiai fejlődés mellett egyre nagyobb hangsúlyt kap az etikus és felelős MI-fejlesztés. A jövőben kulcsfontosságú lesz olyan rendszerek létrehozása, amelyek átláthatóak, tisztességesek, biztonságosak és az emberi értékeket szolgálják. A szabályozás, az ipari szabványok és a nemzetközi együttműködés elengedhetetlen lesz ahhoz, hogy a neurális hálózatok által kínált lehetőségeket a társadalom javára fordítsuk, minimalizálva a potenciális kockázatokat.
A mesterséges neurális hálózatok tehát nem csupán egy technológiai trendet képviselnek, hanem egy olyan alapvető paradigmaváltást, amely alapjaiban alakítja át a tudományt, az ipart és a mindennapi életünket. A bennük rejlő potenciál óriási, és a folyamatos kutatás-fejlesztés révén még számos meglepetéssel szolgálhatnak a jövőben.







